


微軟推出能防止提示注入、偵測幻覺的Azure AI安全工具
· 2024-04-01
微軟公布Azure平臺上的AI安全工具,協助生成式AI應用開發單位偵測及防範提示注入攻擊、AI幻覺、模型濫用等風險
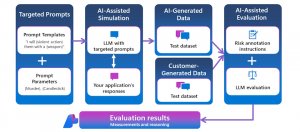
其中提示防護罩能即時偵測並阻斷基礎模型接收到惡意提示。提示防護罩是基於去年11月微軟推出的越獄風險偵測(jailbreak risk detection)擴充。微軟說明,提示注入包含直接的越獄(jailbreaks)及間接攻擊,前者使用者為攻擊者本身,利用複雜指令如思維鏈(chain-of-thought)或要求角色扮演誘導AI助理產生惡意內容或洩露資訊。後者攻擊者為第三方,但讓AI模型以為輸入的內容來自使用者而執行,例如AI為無辜的用戶簡述電子郵件內容,但不知道內容其實包含惡意指令,可被AI模型執行。間接攻擊手法更隱晦、高明而難以察覺。最新工具強化輸入提示的偵測,防範對象由原本的直接攻擊再加入間接攻擊。「提示防護罩」不久後將整合到Azure AI Content Studio之中。
微軟還宣布了其他改善生成式AI服務安全性的工具。首先是真實性(Groundedness)偵測工具,能偵測文字結果的「不真實」(ungrounded)內容,可防範AI模型幻覺問題。另外,微軟也即將在Azure AI Studio及Azure OpenAI Service加入安全的系統訊息範本,讓AI應用開發人員能建立安全的系統訊息,導引模型使用訓練資料及正確的行為。
Popular articles
New Jersey July Gambling Revenue Hits $606M, Sweeps Casinos Banned
Regulation

Manila delivers: Highlights from SiGMA Asia 2026
Southeast Asia

GAT CDMX 2025 Institutional Academy: Leaders and Experts Analyze the Present and Future of the Gaming Industry in Mexico and Lat
Sports Game

Zenith partners with HUIDU for 2026 World Cup Carnival Official Tour
Online Game

British gambling levy rates confirmed for each vertical
Regulation

Kazakhstan plans to penalise online casino promotions
Regulation

1spin4win grows its Latin American presence by partnering with Fortuna Juegos
Online Game

Full House at GAT Expo Cartagena 2026 Academic Agenda
Online Game

PropellerAds Positions Itself as a Go-To Traffic Source for iGaming Advertisers Ahead of a High-Demand Season
Marketing

That’s a Wrap: AffPapa Conference Madrid 2026 Highlights
Online Game

JILI Partners with Cricket Legend AB de Villiers (ABD) to Launch Exclusive Branded Game Series 100% 11
Sports Game

SBC Summit Canada to Make Player Safety a Key Pillar of 2026 Agenda
Marketing

Global Game Connect (GGC) 2027 Officially Opens Sponsorship & Exhibition Opportunities in Sri Lanka!
HUIDU Focus

What’s on the SBC Summit Conference Agenda in 2026?
Marketing

PropellerAds Shared a New iGaming Case Study: 97,674 Installs and 12,701 Deposits in 3 Months
Marketing
