


從發展個別應用到規模化發展,玉山開始思考如何建立一個共用的開發框架,來快速支持業務需求。評估現成開發框架發現無法滿足需求,玉山決定模擬現成框架,自建一套GAI開發框架
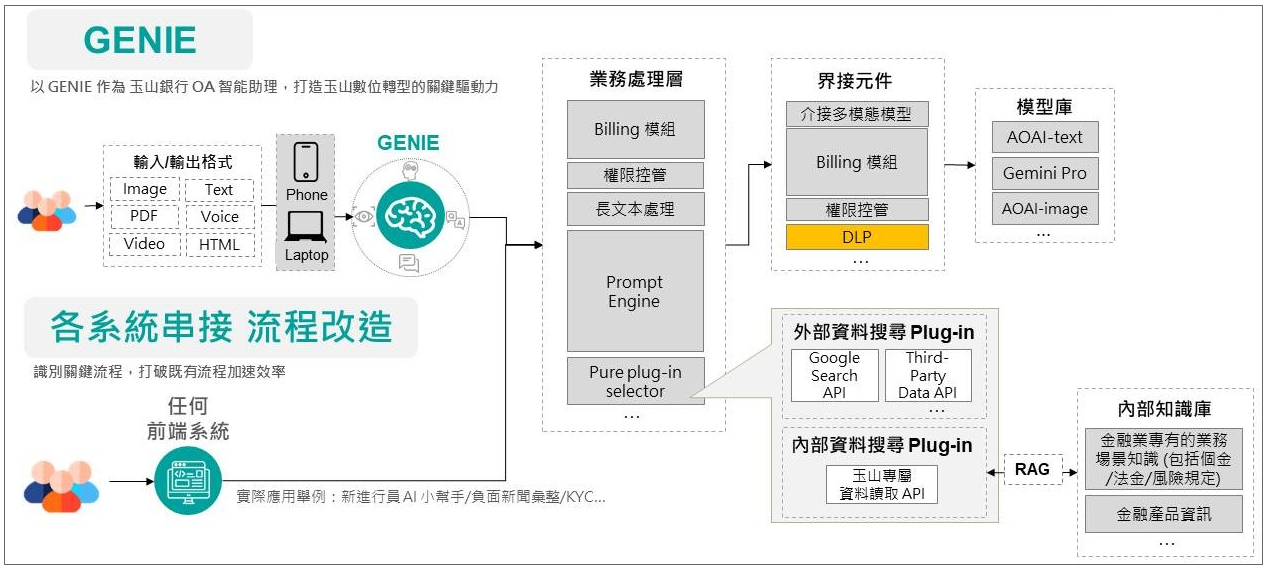
到了今年9月,玉山推出GENIE2.0版,不僅改善了使用者介面設計和平臺背後串接的模型服務,更把平臺基礎架構抽換成可擴充的架構,容易整合更多功能元件。
玉山GenAI平臺GENIE2.0
甚至,GENIE的定位,也從單一API,成為一個能讓業務人員與各種元件溝通的介面。當業務人員和GENIE互動時,表面上是在平臺上進行對話,實際上運用了平臺背後串接的各式元件。除了既有Chatbot服務,玉山內部前端系統也能直接介接GAI應用服務,讓GenAI在無形中輔助業務人員完成工作任務。/玉山金控
建立標準化評測機制,加速測試LLM模型
回應有效性
玉山的GAI應用主要由業務人員和開發人員共同協作完成。業務人員會先提供業務情境,由開發人員提供初版提示,待業務人員拿到提示後,可以在GENIE平臺上進行測試,並和開發人員討論模型回應結果,雙方合作修改多個提示版本後,協作打造出一款GenAI應用。
不過,在修改提示階段,業務人員需要測試多種情境,並和開發人員來回確認測試情境結果,耗時又耗力。
為了加速業務人員測試各種情境,玉山針對各個業務場景,額外設置測試集,透過LLM來為GAI應用評分,將GAI應用評測機制標準化。
建立評測機制後,省下一半的GAI應用開發時長
在建立標準化測試流程時,玉山技術團隊會根據應用類型,切割出需要測試片段和測試種類,明確定義測試流程。再來,業務單位會負責提供測試資料集,包括真人回應的標準答案,以及標準答案對應分數。接著,技術團隊再運用這套資料集,比對真人回應和模型回應結果,以此建立模型回應評分機制。
目前,玉山的測試集可分為兩類,一類是針對搜尋任務設計的測試集,另一類是針對回應內容設計的測試集。
以人資助手為例,由於人資經常舉辦考試,因此,玉山技術團隊使用LLM模擬參與考試的行員。當業務人員修改提示,可以對照LLM參與考試的作答分數,來評測模型回應優劣。若LLM作答分數高,代表業務人員修改的提示、產出的模型回應內容有效,反之,若LLM考試分數低,則代表業務人員需要再修改模型回應。這是玉山其中一種測式模型回應內容的形式。
另外,針對搜尋任務,玉山金控技術團隊在測試集中設計多種搜尋結果,讓業務人員可以判斷測試情境能否有效讓模型搜尋到正確資料,和正確回答問題。例如,當業務人員輸入特定測試情境,業務人員可以得知,模型在測試情境中能否搜尋到正確答案,以及能否正確回答問題,或是,模型能搜尋到部分答案,但無法完全回答問題。另外,LLM會針對模型回應的正確性進行評分,協助業務人員加速測試各種情境。
玉山尚未建立評測機制前,開發人員需和技術人員反覆確認不同測試情境結果,單一應用歷經半年開發時長,才正式上線。建立評測機制後,則節省近一半開發時間,以玉山近期上線的隨行理專為例,僅花三個月,就從實驗走到正式上線。
相關報導 














