


DeepMind正在研究如何帮视频生成声音
支付動態 · 2024-06-18
DeepMind正在发展能够替AI视频生成背景声音的V2A技术,目标是通过自然语言的提示,就能替原本无声的生成式视频,加上相对应且同步的对话、音效或配乐
Google Deepmind
Alphabet旗下的AI子公司DeepMind正在研究如何帮「生成式视频」生成背景声音,利用视频至声音(video-to-audio,V2A)技术来替这些原本无声的视频加上应有的对话、音效或配乐。
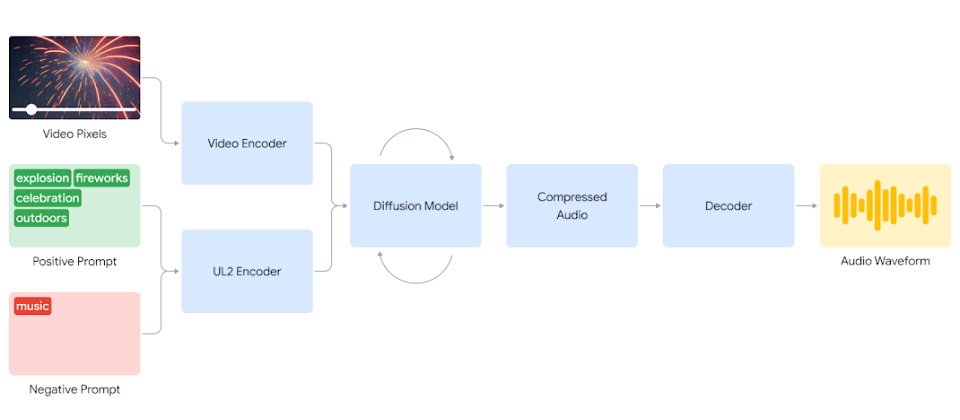
目前DeepMind的V2A技术并不是直接喂入视频就能生成声音,而是结合了自然语言的提示以帮屏幕上的画面配音,兼容于诸如Veo等视频生成模型,并支持包括文件、无声电影等视频内容。
当用户输入音频及文本提示时,V2A便可生成与视频同步的音频波形。它会先将所输入的视频及提示输入数位化,再利用扩散模型反复运算,最终生成一个压缩的声音文档,再由系统将其解码,借以产生与视频画面高度协调的背景声音,完全不需要手动对齐视频及所生成的声音。
在V2A技术的展示视频中,DeepMind团队输入了一个在黑暗中行走的视频画面,再提供「电影、恐怖片、音乐、紧张、混凝土上的脚步声」等文本提示,V2A就能生成恐怖片的背景音乐;还能帮无声的击鼓画面配乐;或是要求它生成搭配画面的海洋音乐。
此外,V2A可替任何视频生成无限数量的音轨,还能选择正向或反向的文本提示,以要求所生成的声音更贴近或远离某些情境。
通过对视频、声音及注译的训练,V2A现阶段已能链接特定的音频与不同的视觉场景,亦能对注释或转录文本中的信息作出反应;DeepMind也正在改善V2A生成结果中关于说话的口型同步能力。
热门文章
巴西颁布新法赋权央行封锁非法博彩账户及 Pix 交易
支付动态

灰度在iGB L!VE 2026展位T70和你相约7月,一起点燃伦敦的热情!
灰度头条

印度最高法院受理公益诉讼,要求全国禁封“伪装”成社交游戏的赌博平台
游戏风向

JILI 宣布与全球板球传奇 AB de Villiers(ABD)达成重磅战略合作
体育游戏

PropellerAds 分享了新的 iGaming 案例研究:在 3 个月实现 97,674 次安装和 12,701 笔存款
广告营销

新泽西州7月博彩收入创6.06亿美元新高,颁布禁令
游戏风向

越南博彩管控逐步放宽,惟本土需求仍显乏力
东南亚资讯

越南在线博彩业政策收紧 催生市场新机遇
东南亚资讯

超级PAC筹资4800万美元:体育博彩势力加码
游戏风向

哈萨克斯坦计划对在线赌场促销活动进行处罚
游戏风向

英国确认各垂直行业的赌博税税率
游戏风向

菲律宾博彩技术赛道迎来新变局,B2B 供应模式加速渗透
东南亚资讯

斯里兰卡博弈产业大转型,官方:剑指南亚拉斯维加斯
游戏风向

巴西拟将博彩税率提高至24% 税收将用于社保和医疗领域
游戏风向

横跨全球6个城市,灰度8场派对邀你共看世界杯,重塑高质量社交新场景
灰度头条
