


苹果发表专门训练多模态模型的AI框架4M,以及运用4M训练而成的any to any视觉模型4M-21,可支持21种模态数据
苹果本周公开展示具备文本、声音、图像理解能力的多模态AI模型训练框架4M,及支持21种模态数据的多模态模型。
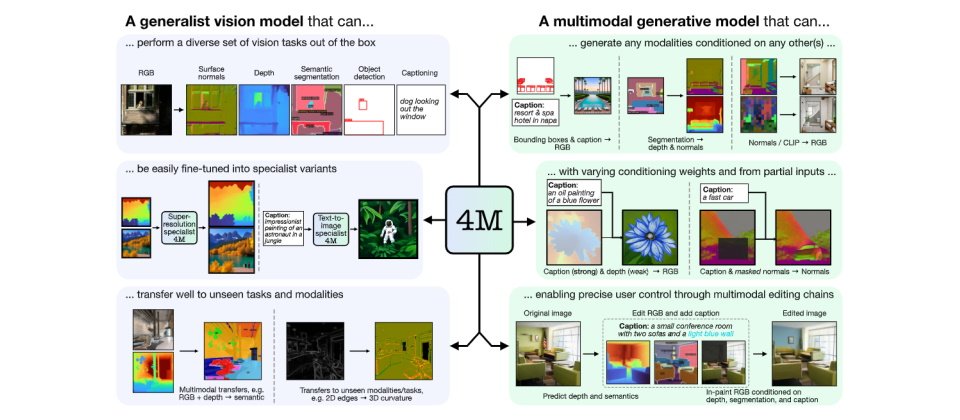
4M模型框架全名为极多模态掩码模型(Massively Multimodal Masked Modeling),为苹果与瑞士洛桑联邦理工学院(EPFL)合作开发。研究团队于去年12月首先在2023年神经信息处理系统(NeurIPS 2023)大会上发表,并向大众开源。今年的最新成果中,研究团队展示4M-21模型,为一any to any视觉模型,可支持21种模态任务和模态。
4M模型及相关技术上,苹果解释,传统视觉机器学习模型只能用于专门化的特定模态或任务,新近的大型语言模型则具备多模态识别能力,而4M则是更进一步的多种模态模型训练方法。它运用掩码建模(masked modeling)方法,来训练出单一统合式transformer encoder-decoder,输出、输入都可支持多模态数据,涵括文本、几何图、语义模态,以及现有艺术模型DINOv2和ImageBind的神经网络特征地图。
苹果说,4M模型框架能以很少量的随机词元(token)训练并有效扩充以训练模型,其主要优点包括可适用多种视觉识别任务,经过微调后,也能在新任务或新模态数据上有效预测,并能训练出现今最夯的生成式模型。
在最新的研究进展下,研究团队将4M扩展为21种模态数据,加入了包括人类姿势和体形、SAM(Segment Anything Model)instances、以及metadata,还提出了针对特定模型的词元化(tokenization)方法。研究团队也成功以4M框架扩展到30亿参数的模型,还能结合视觉与语言数据来进行训练。
研究团队本周也发布了二种模型,包括4M-7及4M-21的代码和模型。4M-21全名为An Any-to-Any Vision Model for Tens of Tasks and Modalities,研究团队声称练出的模型具备未经微调(out-of-box)的极佳视觉识别性能、可运行任何条件及可操控(any-conditional & steerable)生成、跨模态截取、支持多种传感器数据混合的能力。研究人员指出,通过4M及4M-21的研究,他们展示了可解决了多模态数据输入任务,比现行模型多3倍,而且完全不损及性能。
VenturBeat指出,这次公布是苹果过去极少见透明化宣传的行为,显示为了在AI业务上急起直追,苹果逐渐改变行为作风。在6月的WWDC上,苹果宣布将在iOS 18、macOS Sequoia加入和OpenAI ChatGPT的集成,也可能再引入Google Gemini或其他AI模型功能。














