


从发展个别应用到规模化发展,玉山开始思考如何创建一个共用的开发框架,来快速支持业务需求。评估现成开发框架发现无法满足需求,玉山决定模拟现成框架,自建一套GAI开发框架
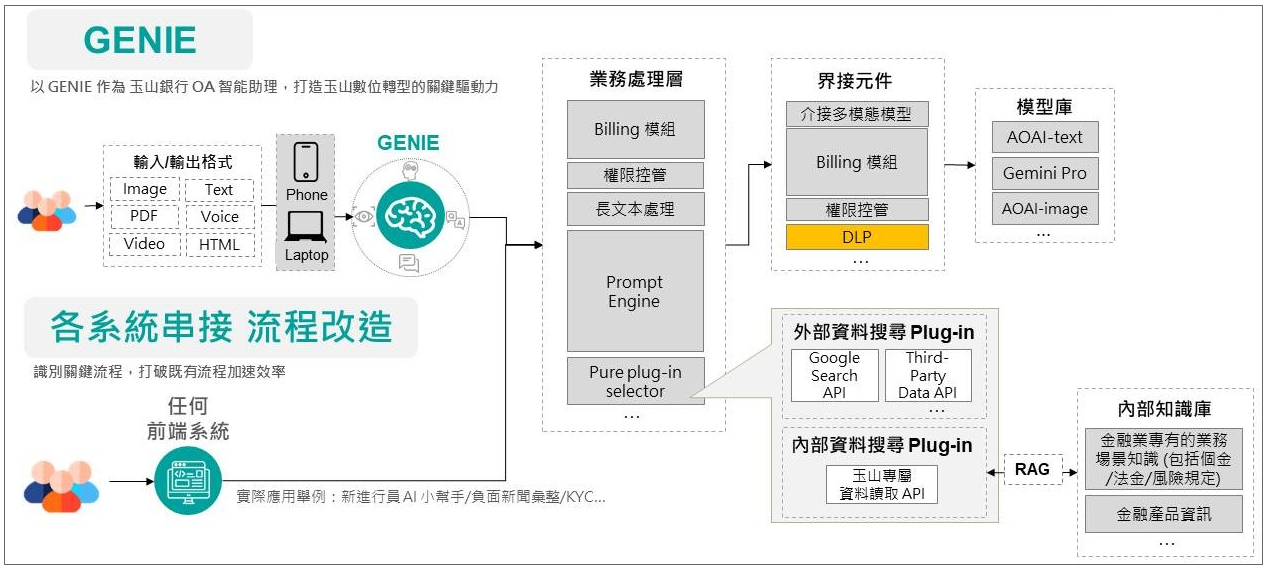
到了今年9月,玉山推出GENIE2.0版,不仅改善了使用者介面设计和平台背后串接的模型服务,更把平台基础架构抽换成可扩充的架构,容易集成更多功能组件。
玉山GenAI平台GENIE2.0
甚至,GENIE的定位,也从单一API,成为一个能让业务人员与各种组件沟通的界面。当业务人员和GENIE交互时,表面上是在平台上进行对话,实际上运用了平台背后串接的各式组件。除了既有Chatbot服务,玉山内部前端系统也能直接介接GAI应用服务,让GenAI在无形中辅助业务人员完成工作任务。/玉山金控
创建标准化评测机制,加速测试LLM模型
回应有效性
玉山的GAI应用主要由业务人员和开发人员共同协作完成。业务人员会先提供业务情境,由开发人员提供初版提示,待业务人员拿到提示后,可以在GENIE平台上进行测试,并和开发人员讨论模型回应结果,双方合作修改多个提示版本后,协作打造出一款GenAI应用。
不过,在修改提示阶段,业务人员需要测试多种情境,并和开发人员来回确认测试情境结果,耗时又耗力。
为了加速业务人员测试各种情境,玉山针对各个业务场景,额外设置测试集,通过LLM来为GAI应用评分,将GAI应用评测机制标准化。
创建评测机制后,省下一半的GAI应用开发时长
在创建标准化测试流程时,玉山技术团队会根据应用类型,切割出需要测试片段和测试种类,明确定义测试流程。再来,业务单位会负责提供测试数据集,包括真人回应的标准答案,以及标准答案对应分数。接着,技术团队再运用这套数据集,比对真人回应和模型回应结果,以此创建模型回应评分机制。
目前,玉山的测试集可分为两类,一类是针对搜索任务设计的测试集,另一类是针对回应内容设计的测试集。
以人资助手为例,由于人资经常举办考试,因此,玉山技术团队使用LLM模拟参与考试的行员。当业务人员修改提示,可以对照LLM参与考试的作答分数,来评测模型回应优劣。若LLM作答分数高,代表业务人员修改的提示、产出的模型回应内容有效,反之,若LLM考试分数低,则代表业务人员需要再修改模型回应。这是玉山其中一种测式模型回应内容的形式。
另外,针对搜索任务,玉山金控技术团队在测试集中设计多种搜索结果,让业务人员可以判断测试情境能否有效让模型搜索到正确数据,和正确回答问题。例如,当业务人员输入特定测试情境,业务人员可以得知,模型在测试情境中能否搜索到正确答案,以及能否正确回答问题,或是,模型能搜索到部分答案,但无法完全回答问题。另外,LLM会针对模型回应的正确性进行评分,协助业务人员加速测试各种情境。
玉山尚未创建评测机制前,开发人员需和技术人员反复确认不同测试情境结果,单一应用历经半年开发时长,才正式上线。创建评测机制后,则节省近一半开发时间,以玉山近期上线的随行理专为例,仅花三个月,就从实验走到正式上线。
相关报导 














