


Google在去年的时候宣布,将要构建一个能够支持1,000种语言的机器学习模型,现在发布阶段性研究成果,Google的通用语音模型(USM)已经能够支持100种语言,这项成果目前发表在arXiv论文预印本网站。
Google在去年的时候宣布,将要构建一个能够支持1,000种语言的机器学习模型,现在发布阶段性研究成果,Google的通用语音模型(USM)已经能够支持100种语言,这项成果目前发表在arXiv论文预印本网站。
研究人员提到,传统的监督式学习方法欠缺可扩展性,要将语音技术扩展至更多的语言,便需要有足够多的资料训练高品质模型。过去资料准备的常见方法,需要以人工手动标记音频资料,而这是耗时且昂贵的过程,更何况对于缺乏资源的语言,更是难以收集足够的训练资料。而自我监督式的学习,反而可以利用纯音频资料,因此更可能达到扩展至数百种语言的目标。
Google的通用语音模型则是使用自我监督式学习,运用大型未标记的多语言资料集预训练模型编码器,并使用较小的标记资料集进行微调,使模型能够识别缺乏资源的语言。通用语音模型具有20亿参数,使用1,200小时的语音和280亿条文本句子进行训练。
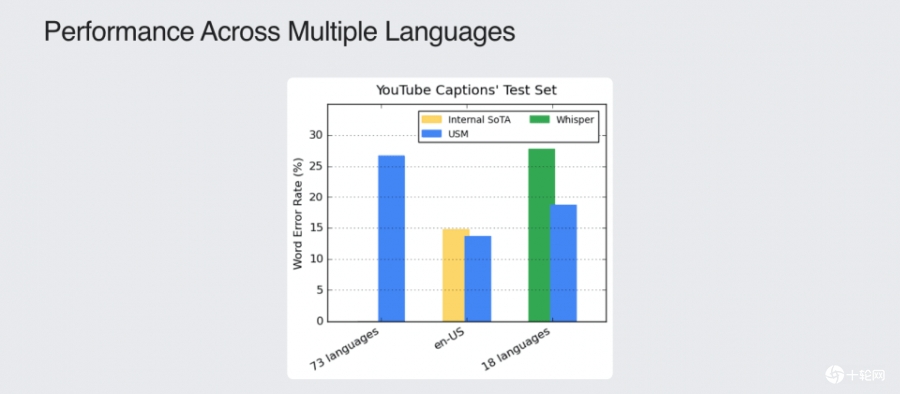
通用语音模型主要用于YouTube,不只可以对英语和汉语执行自动语音识别,甚至还可以识别资源缺乏的阿萨姆语、马达加斯加语和宿雾语等。目前通用语音模型能够对100多种语言执行自动语音识别,尽管该模型所使用的标记训练资料集,仅有Whisper模型的七分之一,但是在跨多种语言的语音识别任务,却有相同甚至更佳的表现。
通用语音模型在其中73种语言,平均每种语言的训练资料不到3,000小时,却实现了低于30%的单词错误率,而这是Google过去从未达到的成果。在各种公开的资料集测试,包括CORAAL、SpeechStew和FLEURS,与Whisper模型相比较,通用语音模型的单词错误率都较低。研究人员还利用CoVoST资料集微调通用语音模型,和Whisper的语音翻译能力进行比较,通用语音模型无论是在资源可用性低、中和高的语言,BLEU分数都较Whisper更佳。














