Google研究人員參考人類的學習方式,提出社會學習框架,使語言模型可以在保護隱私的同時,透過自然語言進行知識共享
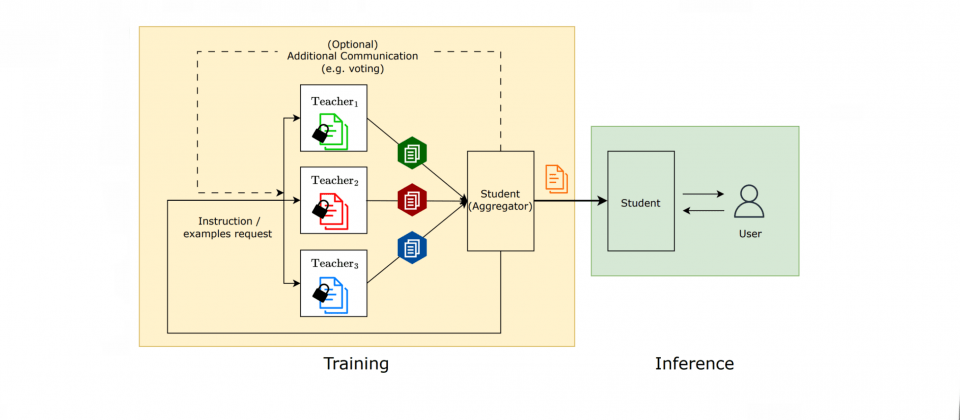
Google公開了一項大型語言模型的創新研究,研究人員提出社會學習(Social Learning)框架,為模型間的知識傳遞開闢新途徑。社會學習使語言模型能夠透過自然語言文字交流知識,由於不需要直接交換敏感資料或是模型權重,因此能確保私密資料的隱私保護。
社會學習的概念就像是人類在社交環境與其他人交換知識的方法一樣,人類向其他人學習常見透過口頭指示,描述參與特定行為的方法,而Google研究人員受人類學習方式啟發,發展出了模型間的社會學習並制定了一個框架,使語言模型也能夠使用自然語言,並在考量隱私保護的情況下共享知識。
在社會學習框架中,學生大型語言模型會向多個已知特定任務解法的教師模型學習解決方案,研究人員透過評估學生模型在各種任務的表現,諸如垃圾短訊偵測、解決小學數學問題,以及根據特定文字回答問題等,來評估社會學習的成效。
研究人員表示,即使語言模型只接收少數範例,仍然能獲得良好的任務解決能力。而這個方式的重要性在於,即便存在隱私顧慮,也能夠實現知識轉移,在研究人員的垃圾訊息偵測任務中,位於裝置上的教師模型從用戶所標記的資料學習,這些資料是將短訊息標記為垃圾訊息或是非垃圾訊息,而在教師獲得偵測垃圾訊息知識後,無須直接分享可能侵犯個人隱私的資料,就可以協助學生模型區分垃圾和非垃圾訊息。
教師模型可以依據實際資料集,合成出新的範例並與學生共享,合成資料集與原始資料雖足夠不同,但是卻又具有相同的教育意義,這樣即便教師模型不直接共享真實原始資料,學生模型仍然能夠從合成資料中學習。實驗結果顯示,當合成範例足夠多,例如只要達到16個,直接共享原始資料,與透過社會學習使用合成資料進行教學之間,模型解決任務的能力就沒有顯著統計上的差異。
研究人員還嘗試了合成指令的方式,讓教師模型針對特定任務生成指令,學生模型依據指令學習執行任務的方式,就如同人類以口頭指令來學習和執行新任務的方式一樣。而實驗證明,生成指令能夠提高模型執行任務的效能,相比於零樣本學習,合成指令能達到與少樣本學習相當的準確性,研究人員表示,這顯示出語言模型在遵循指令上的強大能力。
不過也有部分任務,因為複雜的格式輸出要求,使得教師模型無法提供良好的指令。此外,部分任務合成範例的效果比合成指令表現更好,也有部分任務合成指令可獲得更高的準確性,研究人員解釋,這代表教師模型的教學方法需要因任務而異。
在社會學習中,研究人員希望教師模型能夠在不透露原始資料具體內容的情況下教導學生模型,透過採用秘密共享者(Secret Sharer)方法,來量化過程中可能洩漏資訊的程度。藉由設計金絲雀資料點,來測試教師模型是否會在無意間將原始資料內容透露給學生模型,而實驗證實,教師模型的確僅是運用原始資料生成教學內容,而不是單純複製範例給學生模型。