MLCommons人工智慧模型推理基準測試套件MLPerf Inference v4加入兩個新模型測試,分別是文生圖模型Stable Diffusion XL和開源語言模型Llama 2 70B,而在資料中心分類皆由Nvidia奪冠
MLCommons發布了MLPerf Inference v4基準測試套件的最新結果,其中資料中心分類新增了文生圖模型Stable Diffusion XL和開源語言模型Llama 2 70B,在這兩個新模型的效能表現上,Nvidia系統皆位居第一。而邊緣系統新增的Stable Diffusion XL模型測試,則由Wiwynn提交的系統在效能上獲得領先。
MLPerf Inference基準測試套件涵蓋資料中心和邊緣系統,目的是要衡量硬體系統,在各種場景中執行人工智慧與機器學習模型的速度。MLCommons由專門的工作小組,評估當前階段生成式人工智慧的發展,決定納入基準測試的模型。
在考量模型授權、易用性、部署和決策的準確性,工作小組決定在Inference 4.0套件中加入兩個新模型,一個是具有700億參數的Llama 2 70B來代表大型模型,另一個則選擇用來代表文生圖生成式人工智慧模型的Stable Diffusion XL。
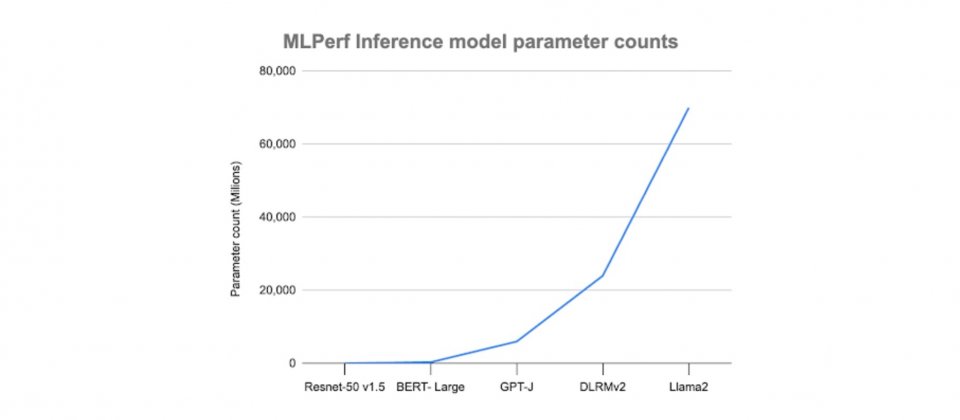
Llama 2 70B相比MLPerf Inference v3.1所納入的GPT-J模型大一個量級,結果也更加準確,工作小組解釋,之所以需要加入一個像是Llama 2 70B這樣的大型語言模型,是因為與較小的語言模型相比起來,執行Llama 2 70B需要不一樣的等級的硬體,而這便成為高階系統一個良好的基準。
而之所以工作小組還選擇Stable Diffusion XL,則是因為其擁有26億參數,透過生成大量圖像,基準測試能夠計算延遲和吞吐量等指標,了解系統整體效能。目前MLPerf Inference v4.0中已經有三分之一的基準測試,是針對生成式人工智慧工作負載,包括了小型、大型語言模型與文生圖生成器,以確保MLPerf Inference基準測試可以跟上最先進的技術。
共有23個組織提交MLPerf Inference 4.0測試結果,包括ASUSTeK、Azure、Google、Intel、Juniper Networks、Qualcomm、Red Hat、Supermicro與Wiwynn等公司,MLCommons共收到8,500個效能結果以及900個功耗測試結果。
MLPerf Inference 4.0資料中心類別中,Nvidia的系統在新加入的兩個模型測試Llama 2 70B與Stable Diffusion XL,皆拿到了效能表現第一,而在邊緣環境的類別,則是由Wiwynn所提交,使用兩個Nvidia L40S GPU所組成的系統,獲得Stable Diffusion XL模型效能表現第一。