


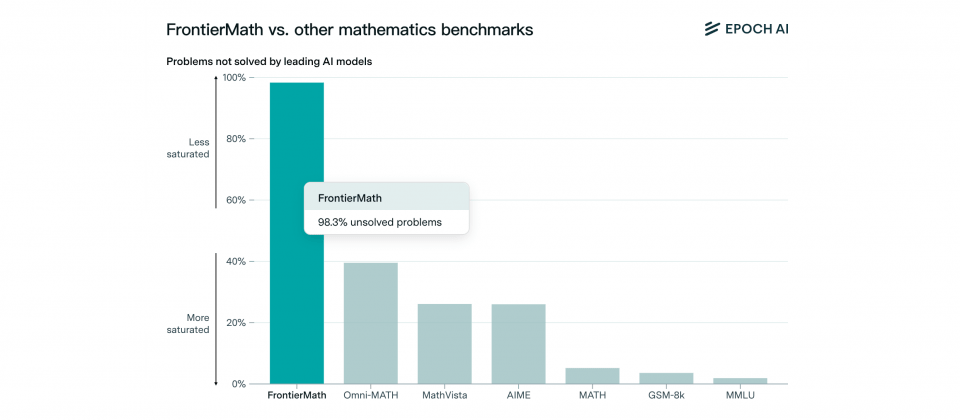
FrontierMath是針對評估人工智慧高階數學推理能力,而設計的數學基準測試,目前市面上知名模型的解題成功率低於2%
Epoch AI
研究機構Epoch AI推出新的數學基準測試FrontierMath,該基準測試的目的在評估人工智慧模型的高階數學推理能力。不同於現有數學基準,像是GSM-8K和MATH,FrontierMath中的數學問題更加複雜且專業,涵蓋現代數學中的數論、代數與幾何等領域,這些題目的難度非常高,專家也需耗費數小時甚至數天才能解答,而這對人工智慧模型帶來全新考驗。
人工智慧在解決高階數學題目上遭遇困難,主要問題在於人工智慧模型通常仰賴訓練資料中的模式來生成答案,而非真正理解和推理問題的邏輯結構,許多模型的解題過程是基於訓練資料中類似問題的模式比對,而不是建立在數學上嚴謹的邏輯推理,這種模式比對的限制,使得模型在遇到稍微變動的數學問題時就容易出錯。
要提升當前人工智慧模型的數學能力,基準測試不只作為評估人工智慧模型數學能力的工具,同時也提供了模型在數學推理能力上具體的進步方向。現有基準測試GSM-8K和MATH,由於問題難度較低,已經被人工智慧模型完全解決,導致無法評估人工智慧數學推理的上限,而新推出的FrontierMath則補充了現有數學基準測試的不足。
FrontierMath的題目皆為專家全新設計,涵蓋多個高階數學領域,難度遠超過其他基準測試。這些題目不僅要求人工智慧理解數學概念,還需要具備複雜情境的推理能力,避免人工智慧透過簡單的模式比對或模糊語言生成方式作答。由於FrontierMath題目的答案通常是大數,或是各種具體或抽象的複雜數學元素或結構,使其具有防猜測的特性,透過猜測獲得答案的正確機率低於1%。
在FrontierMath初步測試中,目前市場上的人工智慧模型表現普遍不佳,即便能夠在GSM-8K和MATH達到近乎滿分,但是包括Claude 3.5和GPT-4o等知名模型,在FrontierMath的解題成功率均低於2%。研究團隊指出,這些挑戰不是透過增加模型規模就能解決,需要在演算法和推理架構層麵深入改進。
多所學術機構的數學專家都參與審查FrontierMath的題目,確保了基準測試的正確性和難度,且不包含任何模糊性。FrontierMath題庫還會持續擴充,官方未來會定期發布人工智慧模型的測試結果,並與人工智慧社群合作以促進學術交流。
目前人工智慧模型在數學推理方面的侷限性,Apple早前的研究也指出同樣現況,人工智慧模型大多依賴訓練資料中的模式來模擬推理步驟,而非進行真正的邏輯推理。Apple研究人員使用改良過的基準測試GSM-Symbolic測試市面上的模型,研究人員發現,即便是小學程度的數學問題,人工智慧模型的表現也受到限制,當改變數學問題中的數字或增加一個額外的無關條件時,模型的解題準確度就會顯著下降,甚至達到65%的跌幅。














